Peter Robinson and Elizabeth Solopova "The Wife of Bath's Prologue on CD-ROM: A Demonstration"
The Project's first major publication, the CD-ROM of the fifty-eight pre-1500 manuscripts and early printed editions of the Wife of Bath's Prologue, was published in April 1996. We will illustrate what we have to say by demonstration from the published CD-ROM.
The Canterbury Tales Project has two major aims. Our first aim is as old as textual scholarship: we want to find out, as nearly as we can, what Chaucer actually wrote. To do this, we have to begin as all textual critics must when faced with a large and complex textual tradition: we have to establish, using all the means at our disposal, a narrative history of the textual tradition. Once we have a clear sense of the sequence of copying of the manuscripts, we can begin to discriminate which manuscripts appear closest to the head of the tradition, and in turn use that information to filter Chaucer's own text from the mass of scribal variation. Though this aim is old, some of the methods we use - computer collation, techniques of computerised stemmatics borrowed from evolutionary biology, database analysis - are very much of the late twentieth century.
Our second aim grows from the first. In order to arrive at a history of the whole textual tradition, we have to gather and analyse every piece of relevant information in every one of the eighty eight pre-1500 witnesses to The Canterbury Tales. That is: we have to acquire copies of each of the 25,000 pages of text; we have to transcribe every word in every page in every witness of the text; we have to collate all these transcriptions word-by-word against one another to create the record of agreement and variation which will be the foundation of our narrative history of the text. We have become aware, as we accumulate this body of information, that we are creating an extraordinary research resource: exact original-spelling transcriptions of some six million words of fifteenth-century manuscript and early printed edition material. Not only this, but we are assigning every one of these six million words to a lemma and a grammatical category, so that it will be possible (for example) to locate every occurrence of the verb 1st person present singular and the second person present singular subjunctive, etc., of the verb to be in all this material. All this, of course, will be useful to us in our search for Chaucer's own text. But clearly it will be even more useful for scholars who may have no interest in Chaucer (unthinkable as it seems, to have no interest in Chaucer): for researchers into the history of the language, into dialect, into orthographic and morphological change.
Clearly, we are not yet ready to say very much about the history of the tradition. Our success, or otherwise, in this first aim can not be judged from this first CD-ROM. However, you will be able to judge from this first CD-ROM how far we might achieve our second aim: the provision of information useful to other scholars.
Here is the opening screen of the Wife of Bath's Prologue on CD-ROM. We are using the program DynaText, from Electronic Book Technology, to present our work. You will see, in this opening screen, the DynaText metaphor of table of contents to the left, and text to the right.
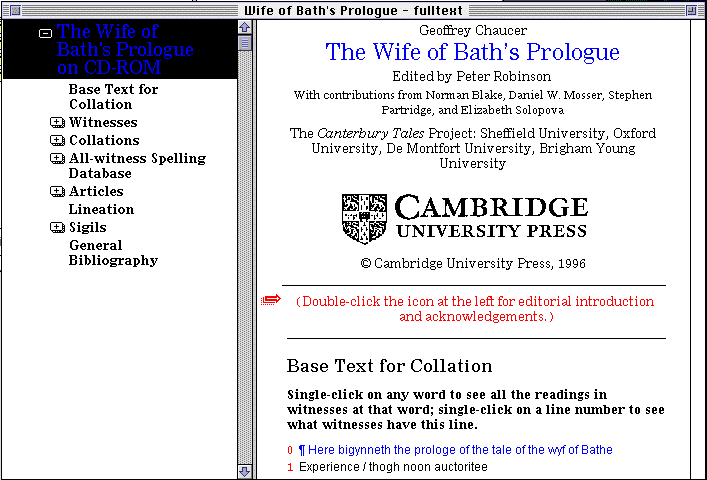
Figure 1: DynaText opening screen
The table of contents gives an immediate impression of the scope of the CD-ROM: sections containing the base text for collation; the witnesses, the collations; an all-text spelling database; articles; and bibliography. On the right hand side, beneath the title and an invitation to see a full electronic title page and introduction, you see the beginning of the base text for collation. This base text is, in essence, the text of the Hengwrt manuscript, very lightly emended. At the head of the base text, a rubric invites the reader to click on any word to see just what readings the witnesses have, or do not have; or, the reader can click on the number beside the line to see what witnesses have or do not have that line. Notice that the numbers beside the line are in red: throughout the CD-ROM, red is used to indicate the beginning of a hypertext link. We follow the invitation in the rubric, and click on the first word of the text proper, Experience. The textual variant screen appears, showing us all the variants at that word:

Figure 2: Textual variants screen
A screen like this will appear for each of the six thousand words in the base text, showing all the variants at that word. A rubric at the top of the screen gives information about available hypertext links. Below this, we are reminded of the line in the base text and of the word in the base text, Experience, where all the readings shown in this screen appear. We are then given the forty-two witnesses which have the same substantive reading Experience as the base text; below this, are the nine witnesses which have the variant Experiment, and so on. The rubric indicates two hypertext possibilities. The first possibility is to see the text of all witnesses to a particular reading, by clicking on the icon to the left of that reading. Thus, clicking on the icon beside the reading Experiment invokes this screen:

Figure 3: Witnesses with Experiment
Here is the text of this line in all nine witnesses which read Experiment. Observe that only one of these witnesses actually has the spelling 'experiment'. In our collation, we have regularized the spelling variation out to leave only substantive variation at this level. We have not discarded the information about spelling variation: as we show later, this information about spelling variation becomes the foundation of the spelling databases, and we also give access to a 'unregularized' collation which retains all the information on spelling (see Figure 6 below).
The first hypertext possibility from the textual variant screen was to see the text of all witnesses to a reading, by clicking the icon to the left, as above. The second hypertext possibility from the textual variant screen is to click on the sigil for any one witness. This will take the reader to that line in the transcription of that witness (you can also reach the same point by clicking on the line for that witness in the last screen). Thus, clicking on the sigil Fi against the reading [..]xperyment takes us to the first line of our transcription of the Wife of Bath's Prologue in the Cambridge Fitzwilliam McClean 181 manuscript:

Figure 4: The Fitzwilliam manuscript in transcription
Note here that we do not show E as the first letter of Experiment but a bracketed ellipsis, [..]. If we want to see what the manuscript actually has, above this first line in the transcription there is a camera icon. If we click on this, a digitised image of this page appears:

Figure 5: The Fitzwilliam manuscript - image and transcription
We can see now why in the transcription the first letter appears as [..]: the scribe left a space for the ornamental capital but this was never executed. Wherever there is a page break in the witness, our transcription shows a camera icon, and you can compare our transcription of any page with an image of the witness just by clicking on that icon. Thus, in this CD-ROM you are never more than a few clicks away from a manuscript image; it is very easy indeed for people to find the mistakes in our transcription.
In Figure 3 above we saw that of the nine witnesses which contained the reading 'Experiment' only one seemed to spell it as 'Experiment'. The collation we gave in Figure 2 was a 'regularized' spelling collation: that is, we levelled out all variations of spelling. We have also included on the CD-ROM a full unregularized collation, in which all the information about all the spellings of every word in everyone of the fifty-eight witnesses is given. You will see in Figure 2 an invitation to click on an arrow icon if you wish to see this unregularized collation:

Figure 6: The unregularized collation
From this screen, you can examine every spelling in every witness at this point. Observe, for example, that of the forty-two manuscripts which have the regularized reading 'Experience' only one (Ma) spells it in the modern way, without any ornamental capital (indicated by the blue text) or abbreviation. Once more, as everywhere on this CD-ROM, the red text indicates a hypertext link: clicking on a sigil for a witness takes you straight to the transcript of that witness on the CD-ROM, as in Figure 4.
You can burrow your way into the witnesses, as this account shows: by moving from the base text to the collation to a transcription to a page image, and so on. The CD-ROM will also permit you to go, very easily, direct to a transcription, or a page image, or many other places. Look again at the table of contents window, here showing the subheadings for the witness Ad1:

Figure 7: The table of contents window
The + signs against some contents entries indicate that further headings lie beneath that entry. Here, clicking on the + beside 'The Witnesses' brings up headings for each of the fifty-eight witnesses. Then, opening up the entry for Ad1 (British Library Additional 5140) as in the figure shows the separate items for each witness: the transcription itself; notes on the transcription; the description of the witness; the transcription of the glosses; a catalogue of all the images of this part of the witness; and finally the spelling database for that witness. You move to any one of these simply by selecting the item you want to see and clicking on it. Here is the introduction to the transcription, pointing out particular difficulties in our transcription.

Figure 8: An introduction to a transcription
Observe again the red text, indicating a hypertext link: clicking on a line number (for example) will move you direct to the transcript of that line in this witness. Then we have a description of the witness, as follows:

Figure 9: A witness description
These descriptions have been prepared by Daniel Mosser, of Virginia Polytechnic Institute and State University (Virginia Tech), as part of his projected new description of all manuscripts of The Canterbury Tales. Over the last fifteen years, Professor Mosser has examined every manuscript of The Canterbury Tales and we are fortunate to be able to present something of the results of his research on this CD-ROM. After the witness description, we present a transcription of the glosses in every manuscript:

Figure 10: Transcription of glosses
The transcription of the glosses has been made by Stephen Partridge, of the University of British Columbia, and we are again fortunate, as we have been with Dan Mosser, to be able to publish this. The transcriptions of the glosses are linked to the transcriptions in the text by hypertext links both in the text and in the glosses. Thus, in this example the arrow in the top window beside line 9 of the transcription of British Library Additional 5140 (Ad1) will take the reader to the gloss on that line, shown in the bottom window. In turn, the red '9' before that gloss in that window will take the reader back to line 9 in the transcription. The note icon at the end of the gloss brings up a note window, in which Stephen Partridge assigns the source (usually biblical) of the gloss.
The last item for each witness is the spelling database. These spelling databases are perhaps the most remarkable and novel feature of the CD-ROM. Here is the beginning of the spelling database for the letter 'B' for the Ad1 manuscript from the CD-ROM:

Figure 11: The spelling database for a witness
Clicking on any lemma (in red, on the CD-ROM) will bring up a summary of all the spellings of that word in that witness. Thus, clicking on 'be', for the verb 'to be', brings up this window:

Figure 12: Summary of spellings of a word in a witness
Here, we are told that there are 221 occurrences of forms of the verb 'be' in thirty-eight spellings in Ad1. Further, we are told that seventeen of these are of the infinitive: twelve as 'be', four as 'ben', one as 'ben' with a flourish; there is one spelling 'Be' for the infinitive in initial position; and so on. If the user clicks on the (4) beside the ben in the window above DynaText will bring up a window showing all occurrences of the infinitive spelt as 'ben' in this witness. Thus:

Figure 13: All occurrences of infinitive spelt ben
It can be seen that in all these, the scribe has used the final -n form to prevent elision with a following vowel. Clicking on the line number to the left will take the reader straight to that point in the transcription. Similarly, clicking on the (12) beside Be in the window shown in Figure 12 will bring up all instances where the infinitive is spelt be in Ad1:

Figure 14: All occurrences of infinitive spelt be
It is notable that the scribe appears remarkably disciplined in his use of the alternative be/ben forms: 'ben' is used consistently to avoid elision, but 'be' is used everywhere else. Note particularly the use of 'be' before a vowel in 554: here the virgule after 'be' prevents elision, and so permits the scribe to use 'be' not 'ben'.
To achieve this lemmatization, we have assigned every instance of the verb to be to the lemma be and then defined the grammatical form for each occurrence of the verb to be: as first person present singular, second person present singular subjunctive, etc. We do this as part of the collation process. Working through the Collate interface, this lemmatisation and part of speech classification can be done extremely quickly. It take us (the two authors) around six weeks to achieve a full lemmatisation and part of speech classification of every one of the three hundred and fifty thousand words in the fifty-eight witnesses of the Wife of Bath's Prologue. There is a spelling database similar to the above for every one of the fifty-eight witnesses on the Wife of Bath's Prologue CD-ROM. Each of these spelling databases contains a record of the 6000 spellings, approximately, of the words in that witness, lemmatised and classified as above.
In addition to these fifty-eight 'single witness' spelling databases, the CD-ROM will contain a single 'all witness' spelling database. This will draw together all the 350,000 spellings in all fifty-eight witnesses into a single database, as follows:

Figure 15: All-witness spelling database
As with the spelling database for an individual witness, clicking on the lemma to the left (in red, on the CD-ROM) will bring up the all-witness spelling database open at that point:

Figure 16: An entry in the all-witness spelling database
This screen shot shows the beginning of the entry for 'be' in the all-witness spelling database. The entry for 'be' is divided into some thirty different parts of speech, with all the spellings for each part of sp eech in all the witnesses grouped together. Hypertext links take the reader to the single-witness spelling database for a given witness (as in Figure 12 above), or to the text of all occurrences of this spelling in a particular witness (as in Figures 13 and 14 above). Similarly, there are hypertext links from every word in the spelling database for each witness to the corresponding position in the all-witness spelling database. Altogether, there are over two million hypertext links on this CD-ROM.
In this account, we have concentrated on what is unusual in this CD-ROM: the presentation of textual variation, both of spellings and of substantive readings, in the context of full-text transcriptions, collations and digital images of each witness. Other parts of this CD-ROM are more conventional. In the 'Articles' section we present writings about our work. Some of the articles republish items published in our first Occasional Papers volume. Others are written specifically for this CD-ROM: thus articles by Dan Mosser on aspects of his witness descriptions. Finally, the 'General Bibliography' presents a bibliography of relevant works.
The fact that we have now published this CD-ROM is sufficient proof that we have found solutions to the major technical problems of making an electronic edition. We say very little in this paper about how we did this work. In essence, we have transcribed all the witnesses into plain text files containing markup in Collate format. We then use Collate to carry out the collations, and to generate all the collations and spelling databases in Standard Generalised Markup Language (SGML). We also use Collate to convert the witness files into SGML. Accordingly, all our work - all transcription, all collation - is done with Collate encoding, which is a much simpler and easier form of markup to use than SGML. Indeed, we very rarely have to see SGML, or work with it directly, but instead rely on the tools in Collate to make the SGML for the CD-ROM. Most of the tools we use will be available in the forthcoming Project edition of Collate, to be released in August 1996.
People expert in computer encoding are rare; perhaps as rare as people expert in Middle English. We could never do our work on The Canterbury Tales if we who work on this project all had to be expert in both computer encoding and Middle English. One of us, Peter Robinson, is proficient in computer encoding. The other, Elizabeth Solopova, feels about computer encoding as Professor Blorenge, professor of French Literature in Nabokov's Pnin, felt about his subject: Blorenge did not know French and disliked Literature. Already, the tools are sufficiently advanced to permit advanced work to be done without specialist computer knowledge. Moreover, the intellectual issues underlying the realisation of electronic editions will press with more and more urgency as the editions mature. We became aware in our work of several major areas of difficulty in what we are doing. We will dwell on three of them: our transcription, our spelling databases, and our understanding of what an electronic edition is.
The benefit of computer readable transcripts and spelling databases is that they enable large scale statistical research designed to produce 'objective results'. But this benefit conceals a trap: at the core of these databases and transcripts inevitably lie interpretative decisions. This paradox is itself reason for caution in the use of such electronic tools, and it imposes a duty of consistency and transparency on those who make the interpretative decisions underlying these data collections. It became evident to us that in order to make our decisions reliable and predictable, our practice had to be very carefully weighed and well documented. All our decisions had to be a compromise between the requirements of consistency, utility and philological exactness, even though these requirements do not always well agree among themselves.
When working out our transcription and lemmatisation policies we tried to minimise the need for subjective decisions on a case to case basis, by simply eliminating some of the possible distinctions. Thus we decided to transcribe all first letters of line initial words in verse as emphatic, in manuscripts where the scribe's usual practice is to use emphatic letters at line beginnings. For some letters scribes do not have distinct emphatic and unemphatic forms, and had we decided to keep this distinction, the choice (emphatic letter or not) would have had to be made 'impressionistically' by every transcriber. This would have largely undermined the value of this information.
When we preferred to keep distinctions which need many interpretative decisions, we brought this to the attention of our readers in the transcription introductions and in the lemmatisation statement. Thus in the transcription introductions to most manuscripts, we say that word division is uncertain and that it was often difficult to decide whether the spelling is as one or as two words. Considerations of precision did not allow us to regularise word division. Nor was it possible to give a single rule for treatment of all such spellings: what looks like one word at first reading may look as two words at a second reading by the same person.
To carry out transcription we had to interpret every potentially significant mark on every manuscript page in accordance with our transcription policy. This was not always easy. In our article on the 'Guidelines for Transcription' (published in the first Canterbury Tales Project Occasional Papers volume and also included on the CD-ROM) we explain our choice of a graphemic scheme: that is, a scheme which aims to preserve all graphemically distinct spellings. Thus, we neither level all spellings to a standard, as is common practice in printed editions, nor do we try to record all information about different letter forms, as in a graphetic analysis. However, given the uncertainties of Middle English scribal practice, it can be very difficult to determine whether particular marks on a page have graphemic meaning; and if they do have graphemic meaning, what meaning.
For example: we have chosen to transcribe as potentially significant marks, tails and flourishes occurring on final letters in many manuscripts. There are cases where flourishes appear to be undoubtedly meaningful: this is often the case with flourishes which stand for final -e in words ending in -re. In some such examples a flourish represents a stressed final -e, e.g. in the word tre in Mm. Potentially meaningful use is sometimes revealed by comparison of manuscript spellings: sire spellings in Hg often correspond to sir with a flourish in El. At the same time tails often seem to have no graphemic meaning. We did not transcribe tails which occur on final vowels. In one manuscript - La (British Library Lansdowne MS 851) - we had to discard the attempt to record tails: they occur after virtually every final letter and are clearly ornamental and not graphemic.
As we carry out the collation, we assign every word in every witness to a lemma, or headword, and declare its grammatical form. This task presents many difficulties analogous to those inherent in our transcription system. It is clearly more useful to other scholars to sort all the spellings by lemma and grammatical category, than just heaping all the spellings into an undifferentiated mass. But it will only be useful if the sorting, the lemmatisation, is appropriate and transparent. It must not be too fine, and therefore risk engaging in precious distinctions which will annoy. Nor can lemmatisation be too coarse, and fail to make the divisions scholars may reasonably expect. Perhaps most important, scholars must easily grasp what distinctions have been made and not made, and why.
Just as it is often difficult to decide how we should represent particular marks on the page in our transcription, so it is often impossible to arrive at a firm decision as to just what grammatical category, or even to what lemma, a particular word should be assigned. Once more, the flux of Middle English over this period makes it difficult to decide just what grammatical categories we should determine. One of the problems we encountered was how to treat such verbs as wol, shal, kan, may and moot: as modal verbs, in anticipation of their modern state, or in the same way as all other notional verbs and so to determine in each case their mood and tense. sholde, for example, occurs both in preterite contexts where it can be perfectly well described as past indicative, and in present contexts, very much as modern English should.
Another example of uncertainty is how to treat such prepositional phrases as to yeere, today, on live, a live, a caterwawed, on honde, a bedde and so on. They can all be spelt both as one word or as two words. Do we treat them as nouns with prepositions, or as adverbs? We wished to reflect the transitional state of the language in our classification: some of these expressions were in the process of becoming 'full' adverbs. In the language of some scribes this process was more advanced than in the language of others, and we wanted this to be shown in our system. Because of this we did not want to adopt one rule for all such cases and to treat them all as, for example, nouns with prepositions. One way was to be guided by the highly irregular word division of the manuscripts, and to consider them adverbs when they are spelt as one word and nouns with prepositions when they are spelt as two words. Thus a liue would be a preposition and a noun (lemmata on and lyf), whereas aliue would be an adverb (lemma aliue). We could also take into account the form of preposition: if it is in a reduced form (a) it is an adverb, if not - it is a noun. However, the reduced form is common for on and of, but not for by or to, for example. This rule would work only for some of the cases.
Our system had to anticipate various difficulties. Thus we have chosen to mark the oblique case of monosyllabic nouns often expressed though final -e. We decided to make this distinction for nouns ending in a consonant, but also for nouns with final -e. This is because some nouns have alternative forms with and without -e, and in such cases it is not clear whether the final -e is due to oblique case or always occurs in this word. An example is the word birthe. It occurs twice in Hg, both times in the form birthe: once in a prepositional phrase in oure birthe WBP 400, and once in objective case that he his birthe took MLT 192. At the same time this word - an early Middle English adoption of an Old Norse endingless nominative - did occur without final -e in Middle English. We have chosen to mark the oblique case of such nouns to avoid prejudgement about the function of final -e.
Very often in our work on the transcription scheme and spelling databases we felt overwhelmed by the need for numerous choices. We aimed at a system that would do justice to the diversity of language of the manuscripts, that would be logical and consistent as far as this is reasonable and possible, and would provide scholars with possibly complete information for research. We do not know how well we met each of these requirements, and we look forward to our work being tested by scholars.
Our most general concern is: just what sort of edition are we creating? Or, to put the question another way: who is going to use this CD-ROM; how will they use it? We have been too absorbed in the last years with the struggle to do this work to consider these questions overmuch. Because there never has been an edition like this before -- indeed we do not know whether it should be called an edition -- we have no answers to these questions. But we do have some hopes. We hope that by bringing the manuscripts so close to the reader, in all their richness and all their confusion of readings and spellings, that we will bring the period, the language, and Chaucer himself far closer to the reader. The fixity of a printed edition distances the text from the reader. We hope that through our many texts the immediacy of each scribe's attempts to understand and to transmit might be borne upon the reader, as they have been borne upon us. It might be feared that, with so many texts, Chaucer's own text might disappear into a miasma of variation. We hope the reverse: that we can help the reader find his or her way though the variation to a clearer perception of what Chaucer did write, and did not write.